Web Posted on: December 10, 1998
A STUDY ON FACIAL ACTION VISUALIZATION ON S-TEL: AN AVATAR BASED SIGN LANGUAGE TELECOMMUNICATION SYSTEM
Tomohiro Kuroda
Kosuke Sato
Kunihiro Chihara
Graduate School of Information Science
Nara Institute of Science and Technology
8916-5, Takayama, Ikoma, Nara, 630-0101, Japan
TEL: +81-743725273 FAX: +81-743725279
E-mail: tomo@is.aist-nara.ac.jp
Introduction
Although modern telecommunication has changed our social communication style so drastically, the audibly challenged cannot take benefits of them based on phonetic media. In order to associate their isolated community together and to increase the quality of their daily lives, a new communication system for signers is indispensable.
Today the deaf use TTY or facsimile instead of telephone. However, with these character based communication systems, they need to translate their sign conversation into descriptive language and to write down or type in. So, they eager a new telecommunication system which enables them to talk in signs.
Nowadays so many research works on computer aid for signers including telecommunication systems for signers are coming. Some of these research works have developed data compression techniques for video stream of sign language; others have developed script-based sign communication methods that translate signs into descriptive languages to reduce transmitted data.
These methods succeeded to compress transmitted data, but the language and non-language information contained in signs is lost due to the above compression or the translation. Unfortunately, they cannot mediate natural sign conversation.
Therefore, Kuroda et al. (1995) introduced a concept of new telecommunication method for sign language integrating human motion sensing and virtual reality techniques.
In this system, a person converses with his/her party's avatar instead of the party's live video. Speaker's actions are obtained as geometric data in 3D space, the obtained motion parameters of the actions are transmitted to the receiver, and the speaker's virtual avatar appears on the receiver's display. Thus, it realizes optimal data compression without losing language or non-language information of given signs. Moreover, users can hide their private information without giving displeased feeling.
The prototype system, S-TEL is experimented on UDP/IP by the deaf and sign experts in Kuroda et al. (1997a). The experimental results clears the effectiveness and the superiority of avatar based communication comparing with video based communication; users could make themselves understood through S-TEL even in lossy and narrow communication channel.
However, the readers lost 25% of the spoken signs because S-TEL didn't treat facial expression. Therefore, this paper discusses the suitable way to visualize facial expressions for avatar based communication.
In this paper, the avatar based communication method in introduced in section 1. In section 2, the texture based facial expression visualization in experimented and the model based facial expression visualization is introduced in section 3.
1. Overview of Avatar Based Communication
In Kuroda et al. (1995), we introduced new telecommunication system for sign language integrating human motion sensing and virtual reality techniques. This method solves natural sign conversation on conventional analogue telephone line.
In this method, a person converses with his/her party's avatar instead of the party's live video. Speaker's actions are obtained as geometric data in 3D space, the obtained motion parameters of actions are transmitted to the receiver, and the speaker's virtual avatar appears on the receiver's display.
This avatar-based communication has following advantages.
- Sending kinematic data without any translation process, this avatar-based communication realizes data compression without losing language or non-language information of given signs. The needed bandwidth of the bi-directional avatar based sign communication is 16Kbps, although that of the bi-directional video based sign communication is 2.2Mbps(Kuroda et al. 1998).
- Sending 3D motions, receiver's terminal can produce signing avatar to increase readability of signs.
- This method can be applied to conferencing or party talking (Kuroda et al., 1997b).
- Visualizing avatar instead of live video, users can hide their private information without giving displeased feelings for his/her party.
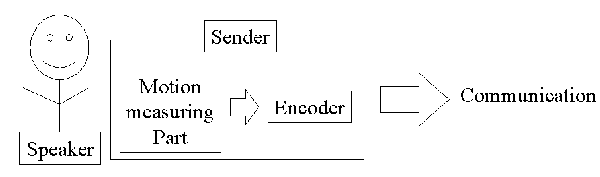
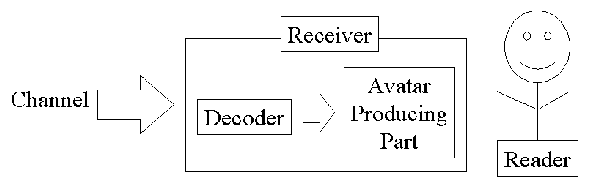
This system consists of following components as shown in Fig. 1.
- Sender obtains signs as geometric data and sends it. Motion measuring part measures hands, arms and upper body motions. Encoder encodes and compresses obtained data.
- Receiver receives kinematic data of signs and displays avatar. Decoder decodes given data into kinematic data. Avatar producing part produces avatar from given kinematic data and display it. This part makes use of reader's viewpoint information if needed. Produced avatar can be virtual CG avatar, robot, etc.
SenderReceiver
Figure 1. Overview of Avatar-based Communication
A prototype, S-TEL, along the design discussed in section 4 is developed as Fig. 7. Kuroda et al. (1996) cleared that 3D stereo scopic view has no effect on the readability of signs and that 2D CG reflecting readers motion parallax is sufficient to realize practical readability. Therefore, S-TEL uses normal 2D display as shown in Fig. 2.
S-TEL sender composed of Pentium 166MHz PC with Windows95, two CyberGloves and a Fastrak. S-TEL receiver composed of Intergraph TD-5Z workstation (Pentium 100MHz with OpenGL accelerator) with WindowsNT 3.51 and a Fastrak. All software components are built on World Tool Kit Ver. 2.1 for WindowsNT and Visual C++ 2.
S-TEL Sender S-TEL Receiver
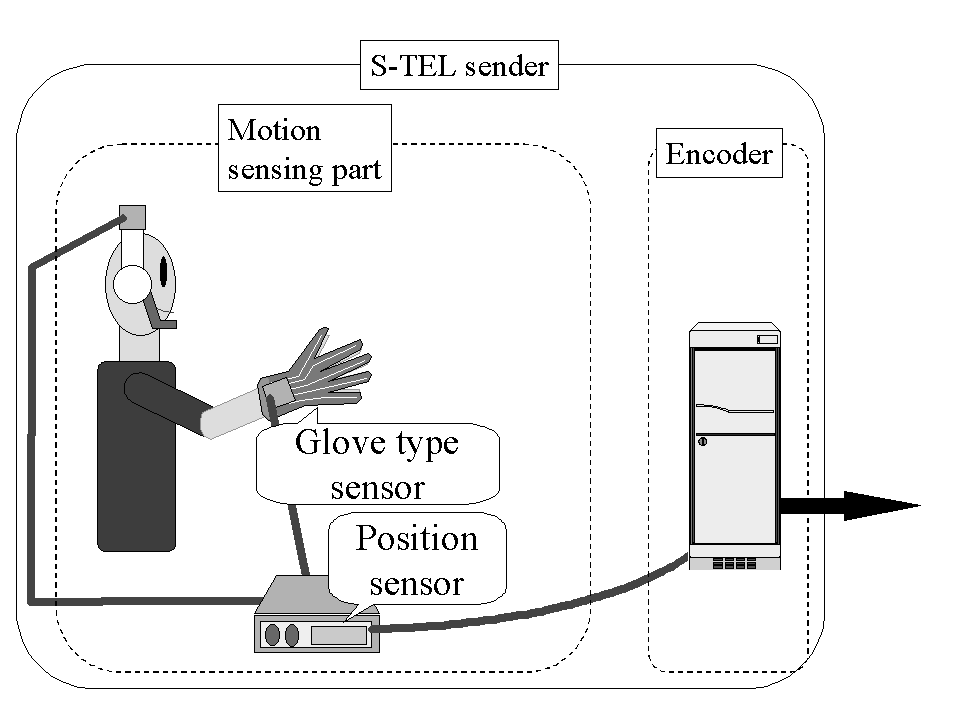
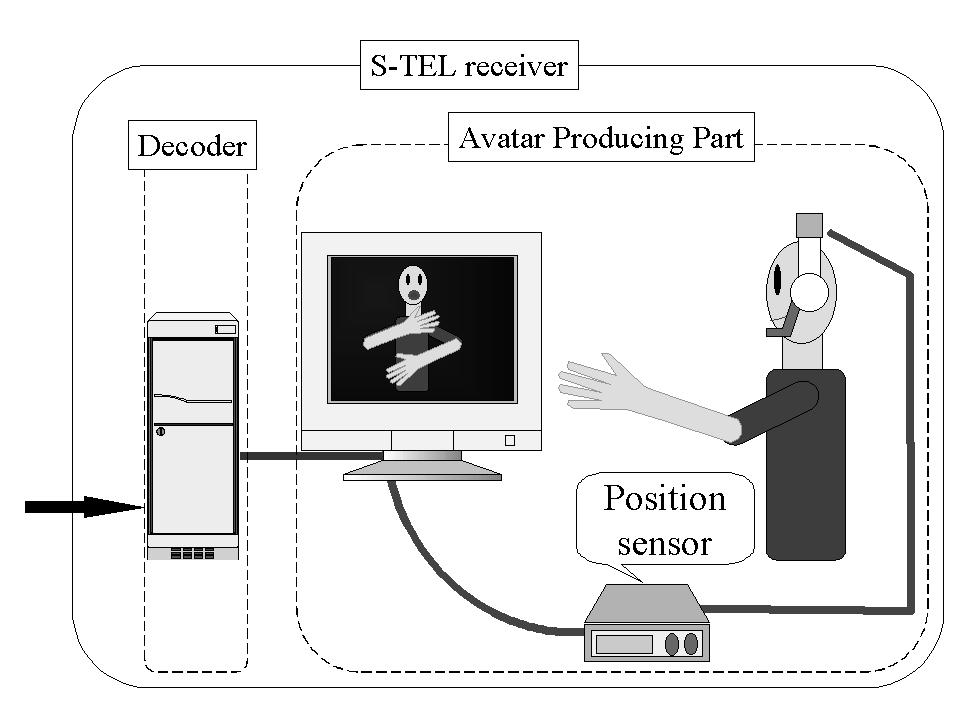
Figure 2. Design Overview of S-TEL
S-TEL is experimented on UDP/IP, and the result shows the effectiveness of avatar based sign communication. However, testees couldn't catch 25% of spoken signs, because S-TEL didn't treat facial expressions.
2. Using Face Texture
The easiest way to visualize facial expressions on CG avatar is to attach facial video image as texture. So we developed signing avatar with face texture as shown in Fig. 3, and experimented on it. The result shows that the readability of given signs are drastically progressed, but the real facial video texture doesn't matches visually with CG avatar image.

Avatar with face texture
Figure 3. Using video texture
We can distinguish the facial expressions of the characters in cartoons written by line drawing. In addition, facial expressions that appear in sign conversations are mainly given by motion of lips, eyebrows and eyes. These discussions derive an idea that the edges of face can express most of facial expressions.
Therefore, we tried to add facial texture, which contains only the edges of speaker's face as shown in Fig. 4. The realized frame rate is 25 frames per second for body motion and 10 frames per second for face texture. The experimental result shows that the given signs are enough intelligible and the visual mismatch between the texture and the avatar is decreased, but that the frame rate of face texture is not enough for lip reading.

Avatar with edged face texture
Figure 4. Using edge texture
3. Using CG primitives
As mentioned above, the method to attach facial image texture on avatar has some serious problems. The visual mismatch between the face texture and the CG avatar, the huge data of the face images and the slow frame rate of face texture. Therefore, we decided that the system encodes the facial expressions by the model based encoding method (Harashima et al, 1989), transmits it and visualizes them using CG primitives. From the research result of sign linguistics, we selected the 21 points as facial feature points as shown in Fig. 5. The points denoted with white circle is for registration, and the point C and D are on the top of the cheekbones.
Facial Feature Points
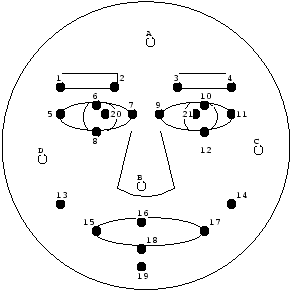
Figure 5. Facial feature points for sign conversation
Morishima et al. (1993) says the movement of feature points can be coded by six bits. Therefore, assuming 30 frames per second bi-directional communication, 8Kbps is enough to transmit facial expression. As Kuroda et al. says that 16Kbps is enough to send body motion, the needed bandwidth for avatar based sign conversation is 24Kbps. Thus, avatar based sign conversation is available on conventional analogue telephone line.
Conclusions
This paper discussed the method to visualize facial expression in avatar based communication. The method to add facial texture has some serious problems, although it is easy to realize. On the other hand, the method to use CG primitives can be realized on conventional analogue telephone line, and it can avoid visual mismatch. Based on this discussion, authors are developing the transmission method of facial expression in progress.
When avatar based sign communication system with facial expression gets popular among Deaf widely, their isolated community would associate together. The system would increase the quality of their daily lives.
Acknowledgement
This study is cooperated with Kamigyo Branch of Kyoto City Sign Language Circle "Mimizuku" and Kamigyo Branch of Kyoto City Federation of Deaf.
References
Hiroshi Harashima, Kiyoharu Aizawa and Takahirop Saito: "Model-based analysis synthesis coding of videotelephone images: Conception and Basic Study of Intelligent Image Coding", Transactions of the {IEICE}, Vol.72, No.5, pp.452-459, (1989)
Shigeo Morishima and Hiroshi Harashima: "Facial Animation Synthesis for Human-Machine Communication System", Applications and case studies, Vol.2, pp.1085-1090, (1993)
Tomohiro Kuroda, Kosuke Sato, Kunihiro Chihara: "System Configuration of 3D Visual Telecommunication in Sign Language", Proceedings of the 39th Annual Conference of the Institute of Systems, Control and Information Engineers, ISCIE, pp.439-443, (1995) Japanese
Tomohiro Kuroda, Kosuke Sato, Kunihiro Chihara: "S-TEL: A Telecommunication System for Sign Language", Conference Companion of Asia Pacific Computer Human Interaction APCHI'96, pp.82-91, (1996)
Tomohiro Kuroda, Kosuke Sato, Kunihiro Chihara, "S-TEL: A Sign Language Telephone using Virtual Reality Technologies", Proceedings of CSUN's 12th Annual Conference Technology and Persons with Disabilities, KURODA_T.TXT,(1997a)
Tomohiro Kuroda, Kosuke Sato, Kunihiro Chihara, "S-TEL: VR-based Sign Language Telecommunication System", In Abridged Proceedings of 7th International Conference on Human-Computer Interaction (HCI'97), pp.1-4, (1997b)
Tomohiro Kuroda, Kosuke Sato, Kunihiro Chihara: "S-TEL: An Avatar Based Sign Language Telecommunication System", Proceedings of the 2nd European Conference on Disability, Virtual Reality and Associated Technologies, pp.159-167, (1998)